원핫 인코딩과 라벨인코딩을 왜 사용할까?
범주형 데이터의 경우 문자로 표현된 경우가 많습니다. 이것을 숫자로 치환하기 위해 사용됩니다.
상황에 따라서 다르지만 원핫 인코딩은 주로 데이터 범주끼리 영향을 끼치면 안될 때 사용되고 라벨인코딩같은 경우에는 범주형 데이터의 관계가 있을 때 사용합니다.
예를 들어 과일데이터인 경우 숫자가 원핫 인코딩으로 변환할 경우 데이터 3가지 모두 1과 0 으로 표현되어 숫자로 변환되어도 해당 범주가 아니면 학습할 경우 영향을 끼치지 않습니다.
하지만 과일데이터를 라벨인코딩한 경우 알파벳 순으로 숫자로 변환되는데 범위가 커져서 만약 1000개의 데이터의 과일이 존재하면 모두 상관없는 똑같은 과일이지만 1000번째 과일이 숫자가 더 커 영향을 더욱 끼치는 현상이 발생할 수 있습니다.
따라서 라벨 인코딩을 사용할 경우 나이대 별 데이터, 각 졸업에 대한 학력 데이터 등 숫자가 커지면서 의미가 있을 때 사용할 수 있습니다.
원핫 인코딩
| 과일 | 가격 |
| 사과 | 1000 |
| 배 | 1500 |
| 포도 | 1200 |
| 사과 | 배 | 포도 | 가격 |
| 1 | 0 | 0 | 1000 |
| 0 | 1 | 0 | 1500 |
| 0 | 0 | 1 | 1200 |
사과 배 포도는 원래 과일이란 컬럼 안에 존재했습니다. 여기서 사과 배 포도를 각각의 컬럼으로 만든 후 해당하는 범주를 1로 표시하는 것이 원핫 인코딩입니다.
라벨 인코딩
| 과일 | 가격 |
| 사과 | 1000 |
| 배 | 1500 |
| 포도 | 1200 |
| 과일 | 가격 |
| 1 | 1000 |
| 2 | 1500 |
| 3 | 1200 |
사과, 배, 포도를 단순히 숫자로 순서대로 변환하는 것이 라벨인코딩입니다.
코드로 구현
원핫 인코딩
import pandas as pd
df = pd.read_csv("fruit.csv")
print(df)
df = pd.get_dummies(df)
print(df)

pandas에 있는 get_dummies를 이용해 원핫 인코딩을 할 수 있습니다.
sklearn에서 제공하는 OneHotEncoder 로도 구현 가능합니다.
from sklearn.preprocessing import OneHotEncoder
import numpy as np
import pandas as pd
df = pd.read_csv("fruit.csv")
print(df)
price = df["price"]
fruit = df["fruit"].to_numpy()
fruit = fruit.reshape(-1,1)
oe = OneHotEncoder(sparse=False)
oe.fit(fruit)
oneHotData = oe.transform(fruit)
fruit = pd.DataFrame(oneHotData)
pd.concat([fruit, price], axis=1)

sklearn 원핫인코더 같은 경우 해당하는 범주 컬럼을 따로 불러와서 원핫 인코딩을 진행해야해서 판다스에 존재하는 get_dummies를 이용하는 것이 더욱 간편합니다.
라벨인코딩
from sklearn.preprocessing import LabelEncoder
import pandas as pd
df = pd.read_csv("fruit.csv")
print(df)
le=LabelEncoder()
df["fruit"] = le.fit_transform(df["fruit"])
print(df)
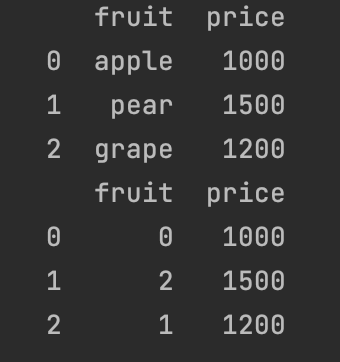
라벨 인코딩도 sklearn에서 제공하는 LabelEncoder 를 이용해 쉽게 변환 할 수 있습니다.
'머신러닝 > 공부내용' 카테고리의 다른 글
| 독버섯 분류 딥러닝 모델을 이용해서 분류하기 (0) | 2022.12.22 |
|---|